

I'm a professional Software Developer and Developer Relations Manager.
My first love will always be Ruby but I'm writing a lot of JavaScript these days. I specialise in Automated Testing and work at Sauce Labs.
I truely believe that crafting Software is how I can best make the world better for its inhabitants, and I love educating and mentoring folks to who'd like to do the same.
Fellow GentleHackers, if you've ever found yourself engaged in a serious attempt to acquire another language you have no doubt discovered it to be a quite onerous practice. Indeed, several practices, as language learning requires one to tune one's ear, learn grammar & vocabulary, parse texts and produce utterances, often altogether.
As such, it won't surprise that researchers have conducted significant research into the relative efficacy of learning practices, and reached some tentative conclusions. One such conclusion is that it can be quite a boon to have a source of both textual and audio examples of comprehensible input.
Tatoeba is one such boon, being a large, community driven database of cross-language sentences, with their respective translations and, quite often, spoken examples. Sadly, only quite often; examples are added by kind and generous community members, so may be absent for any given phrase.
We shan't let that stop us! Let us make use of ElevenLabs.io's splendid AI text to speech faculties to build a browser extension that generates missing audio on demand. Given ElevenLabs' excellent articulation, cadence, and emotional inflection, along with the ability to stream audio via HTTP, our challenge lies primarily in wiring our apparatus together.
The Setup
ElevenLabs Access
Get an API Key
You shall need an API key and a chosen voice. Easily obtained; Sign up for their free plan thusly. (This is an affiliate link, as the GentleHacker is not above securing additional funds, should his recommendations prove useful.)
Make note of the API key, which you may find in your profile; The button to the bottom left.
Choose a Voice
ElevenLabs has a wealth of voices to choose from. Should you wish to use a community-created voice, you can peruse the voice library. Once chosen, click "Add to VoiceLab".
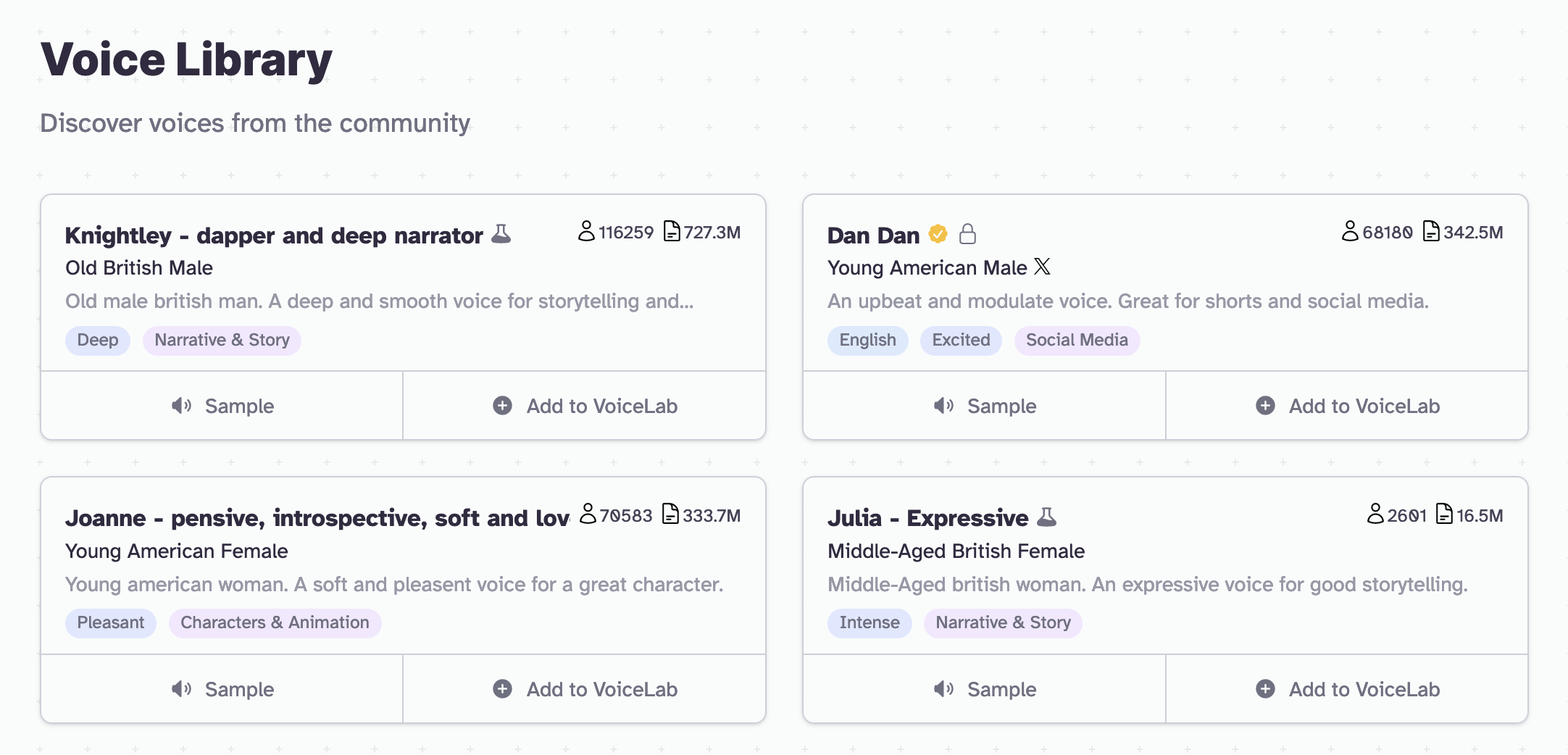
That done, open the Voice Lab and click the "ID" losenge to copy it to your clipboard.
Alternatively, if you'd prefer an official voice, that is... less simple. Those are found in the Speech Synthesis section. Once you've found a voice you enjoy, you can either use the /getVoices method of the API to find the ID, or you can open the developer tools, generate a speech sample, and grab the voice_id from the path of the POST made to /api.elevenlabs.io/v1/text-to-speech/voice_id_is_this_bit .
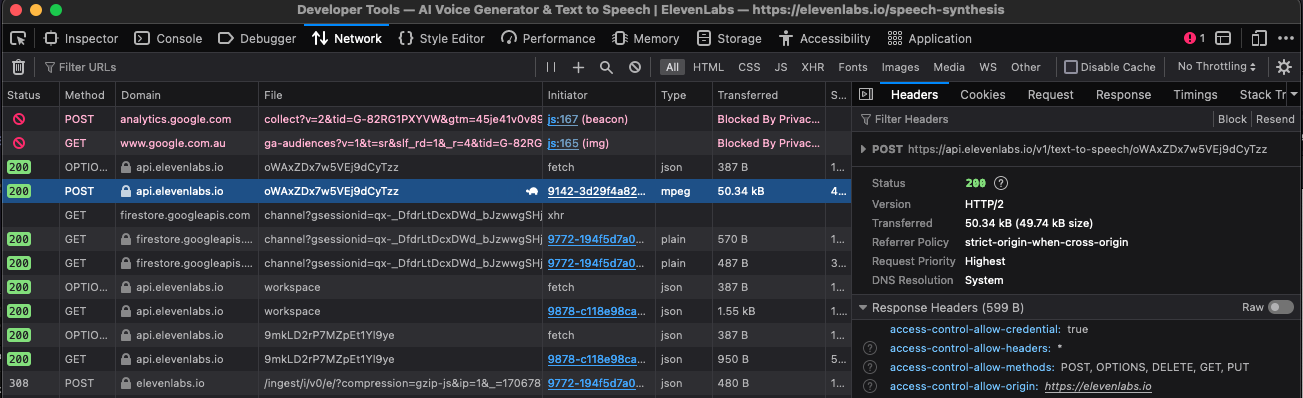
This is a little inelegant, but I was unable to find a superior method. We prevail.
(Oh, and by the way; I recommend choosing the Eleven Multilingual v2 model; the documentation claims it is of slightly lower quality but the non-English output is more verisimilar to reality.)
The Web Extension
Web Extensions are little more then a bundle of webpages, along with guidance to the browser about how they ought be used. There's an ersatz standard. The browsers somewhat follow it.
As such we could hand-write some HTML, some Javascript, a smidgen of CSS and a skerrick of JSON and have ourselves a functional extension.
We could. But no.
It is 2024 as I pen this missive, and I enjoy the conveniences of Svelte, and Vite, and TypeScript far too stridently to hand-carve my extension. Some brief research revealed vite-plugin-web-extension, by Aaron Linker. A brief npm create vite-plugin-web-extension and it provided the shell of a functional extension, with the ability to use Svelte components and rely on Vite's hot module reloading. Delightful.
I also installed tailwind-css, along with flowbyte-svelte, (a component library unfamiliar to me; I deemed this a good opportunity to play), and the webextension-polyfill, to provide missing web extension methods in Chrome
npx svelte-add@latest tailwindcss
npm i -D flowbite-svelte flowbite webextension-polyfill
Fetch and Playback of Speech
But first, a brief detour for configuration
As one might imagine, ElevenLabs requires that one identify oneself when making API requests. We require some means by which our user can provide said API key, and the Options UI, combined with the Web Extension storage API, seems the perfect way to do so.
In our manifest.json, we can specify the URL to a page to present as part of the extensions options. We also need to request access to the storage API for the domains we intend to make use of it upon.
Storing our API Key
Options.html loads our Options component, which, despite appearance, is a fairly simple affair. Here's the meat of it:
When the user enters their key and clicks "Save", we take the following steps:
Get the key from the DOM
Validate the key by requesting this user's details from the API, providing the key via the
xi-api-keyheaderIf successful, generate a truncated version of the key, and store both the full and truncated versions in local storage as
eleven_labs_keyandtruncated_eleven_labs_keyrespectively.
This approach provides the user with two conveniences. Firstly, it allows the user immediate knowledge of whether their key is operational (and thus, that any bugs are due to the extension). Secondly, displaying the truncated key allows users to check they've already saved the correct key.
Retrieving our API Key
When we wish to use our API Key, we can retrieve it from storage. However, we also need to keep our code abreast of changes to said key, in case our user should replace the key whilst our other scripts are already loaded. Let us make use of storage.onChanged.addListener to do just that.
Now, we may fetch our speech
Selecting a Generation Method
The ElevenLabs API provides three methods for generating speech.
Firstly, the Text-to-Speech API operates in a traditional HTTP fashion, generating all audio data then returning it once complete.
Secondly, the Text-to-Speech Streaming API begins streaming audio data as soon as it's available, allowing for faster playback (especially for longer audio passages). This is what we shall make use of.
Thirdly, the Websockets API provides real-time audio responses over a, well, WebSocket. It is intended for situations where the input is not entirely available up front, or where word-to-audio concordance is required.
Calling the API
Let us package the code for retrieving and playing audio data in elevenAPI.ts. We start with data retrievall; as fetch in modern browsers can provide a readableStream, it is eminently suitable for our purposes.
There are three parameters of note. We provide optimize_streaming_latency on line 9, which (according to the documentation) provides us with 75% of the maximum latency optimization, at the cost of "some" quality. I consider this fair; Language is not always heard in ideal situations!
The output_format on line 10 indicates how our audio shall be encoded. We choose PCM, as this is the closest to what the Web Audio API consumes. More on this topic later. Should we care to, ElevenLabs could also furnish us with MP3 or μ-law, all at a range of sample rates.
Lastly, we choose the eleven_multilingual_v2 model on line 20, as this model supports the widest range of languages; ElevenLabs will determines which language is in use automatically, which is rather handy!
Note also, the retrieval of our apiKey on line 5. Because we must await the storage API, we are unable to load the key when this module is imported, due to the harsh realities of Top Level Await. To avoid calling the storage API needlessly, we only do so if apiKey is not already defined, using the ternary operator.
Playback
The Vexation of Audio Formats
The question of playing out audio back brings up a slight quibble. A vexation. One might call it inconvenience, perhaps even a botherance. Were we using the non-streaming API, we'd convert our data into a blob URL and provide it to a HTML5 <audio> tag. We, brave hackers, opted for streaming instead and, as such, will be receiving a series of chunks of audio in lieu of one complete file.
I apologize in advance, gentle reader, for the number of times you are about to read the word chunk.
We rely on the auspices of the Web Audio API to make use of our chunks. It furnishes us with the ability to play individual buffers of audio, albeit with one futher peevishment. Recall when I mentioned that the PCM data returned by the API is the closest to that required by the Web Audio API? Well, closest here won't do. The Web Audio API requires PCM to be encoded as:
(signed) 32-bit linear PCM with a nominal range between
-1and+1, that is, a 32-bit floating point buffer, with each sample between -1.0 and 1.0
Whereas the Elevenlabs API returns signed, 16-bit integer PCM, whose values are not between -1 and +1.
Compounding our difficulty, the ReadableStream is Uint8, an 8-bit unsigned integer TypedArray, meaning we shall have to first convert it to Int16, signed 16-bit integer and thence to Float32, signed 32-bit float.
Converting the response to Float32
Firstly, our type signature and read loop. Our function will take the incoming stream, which is a ReadableStreamDefaultReader. Because we generate this within a try/catch block in doFetch, there's chance it will be undefined.
streamReader; if undefined the optional chaining operator ?. will spare us from exceptions, and the false-y nature of undefined will terminate our loop.We are also providing a Function called fn, which takes a Float32Array and can return anything. This function will be called once for each decoded chunk, allowing us flexibility in how we manage the decoded data.
Once the reader indicates that our stream is complete, we exit the loop.
Our data processing is managed in the section marked // Omitted for brevity, which is supplied below.
As we read each chunk, we encounter another vexation of streaming. Our 16-bit data is encoded as an array of 8-bit responses, meaning each 2-byte value is split into two 1-byte values. Furthermore, there is no guarantee that each chunk contains an even number of bytes.
This necessitates we keep track whether we have a leftover byte or not, every time we process a chunk. If so, the next chunk needs to have said byte appended at the beginning. Frustratingly, it's not possible to add elements to a TypedArray, so we must resort to using the spread operator to create a new array containing the old one.
Once we've dealt with vexatiously odd chunk lengths, we need to deal with our signing issue.
The DataView we've created on line 16 can see all of the data in the chunk's underlying buffer, and allows us to call getInt16 to read any two bytes, in any position in said buffer, as though they were a signed, 16-bit integer.
Because we're consuming two bytes to generate each value, the resulting Float32Array only needs to hold half as many elements. We can then convert the Int16 values to Float32 values (Which we will discuss shortly) and that's that.
Why the Divide?
You may be wondering, why half as many, instead of one quarter?
Think of the conversion thusly. Say you download a 10x10 image from an API, which returns an array containing each pixel's red, blue, and green value, one after the other, until a full 300 element array is in your possession.
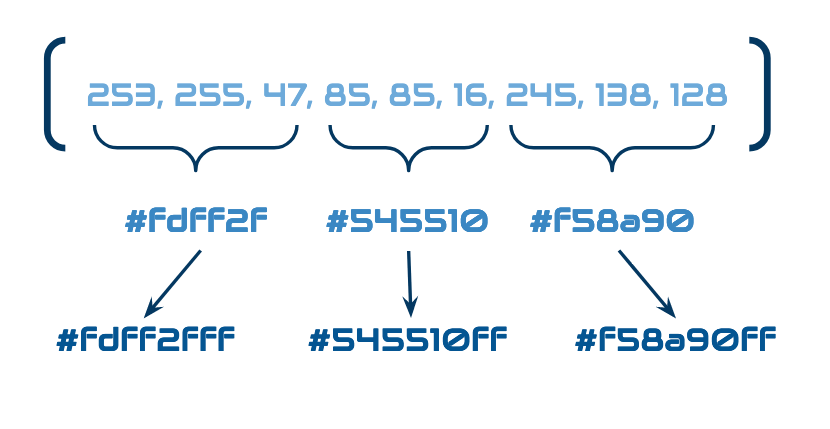
Once you've fetched your array, you convert it into the corresponding hex representation; You now have one hundred elements where previously you had three. Say you now need to feed this image into one which supports hex with opacity. You don't have opacity values, so you convert your values and default to "full opacity" (ff). Each individual value now has more data, but you do not have more values.
When we converted our audio data, we were doing something similar. To go fromUInt8 to Int16, we required two unsigned bytes to combine and decode into one, two-byte long signed sample. We then have to convert each sample to Float32 to please our Web Audio API master. Because signed 16-bit values range from -32768 to 32767, and we need a range between +1 and -1, we can convert our Int16 values to Float32 by dividing by 32768. Each sample has more (empty) data but the number of samples remains the same.
Using the Web Audio API for Playback
The Web Audio API api possesses a helper method called decodeAudioData(), which plays back an AudioBuffer obtained from the likes of fetch... Alas, it requires the full file be ready, and so is not suitable here. We shall have to make our own pudding, as it were.
All online Web Audio processing takes place within an AudioContext, which represents a graph of audio processing nodes. Should one be not averse, one can use the Web Audio API to perform a substantial array of audio generation and processing. Handily, we are spared such complex manipulations.
Our playback handler needs merely create an AudioContext and return a function which will do naught but play back each chunk at the appropriate time. Said function can then be passed to processStream().
As processStream() receives each chunk, it requests a single-channel AudioBuffer of the appropriate length and sample rate from the AudioContext. (The 1 in the call to createBuffer() indicates how many channels the buffer should possess).
The chunk's data is then copied to the first channel therein, and the entire buffer encapsulated within an AudioBufferSource (also kindly provided by the AudioContext). That AudioBufferSource is then connected to the AudioContext's destination, which, by default, is the system audio output. Then, it's scheduled to start.
Timing in the Web Audio API is interesting, as it's driven by the API itself. Each AudioContext has a currentTime, a Double measured in seconds. Each source can be started at any given positive time, also in seconds, and if the requisite time has already started, the source begins immediately.
This furnishes us with an extremely simple means of scheduling, as well as providing an optional delay. We can simply start each sample at 0 + delay + already_queued_samples. This delay also acts as a simplified cache; delay the start of playback by a short period to allow extra audio to be streamed.
Some Interface Niceties
Connecting doFetch(), playHandler() and processStream() is a straightforward process; we invoke doFetch() with our desired text and voice, pass the streamReader to playHandler(), then pass the returned function to processStream(). Our audio now streams without further intervention.
After adding some nice defaults, I also added a method to return the entire audio data, as well as both stream and return the audio. These are left as an exercise for the reader.
Enhancing Tatoeba.org
Finangling the Front End
Our work thus far is, sadly, of no import if we do not provide our user a means of requesting a sentence be generated. Let us now turn our attention to the same.
Web Extensions allow one to inject scripts into the body of webpages. They are called content scripts and may be injected either programmatically, or by specifying the pages in advance. We return to the manifest and instruct our extension to insert src/addMissingVoices.ts on every page of the tatoeba.org domain:
The Lists Page
I chose to restrict my initial version to Tatoeba's lists feature, whereby users can save lists of sentences. Taking a look, we see the greyed-out, muted volume icon indicates the absence of a spoken example.
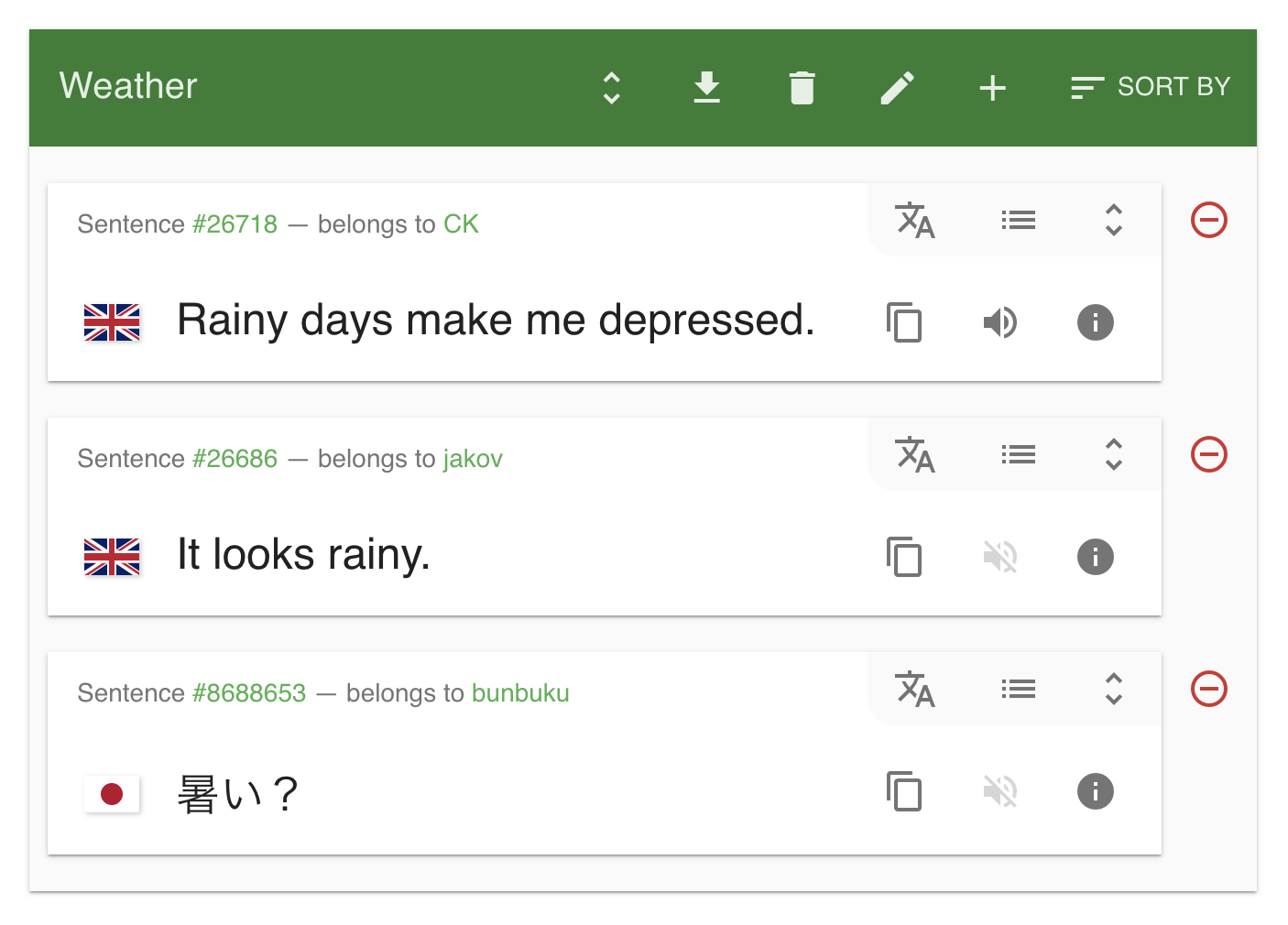
We are thus presented with two challenges:
Extract all sentences within a list for which no example exists
Provide a user interface action allowing them to generate said example on demand
Let's tackle each in turn.
Whither Missing Examples?
In days of yore, a developer might reach for old friend JQuery when interrogating the DOM. We wish to keep our extention's code light and fast, so we shall rely on built in facilities whereever possible.
By peering through the DOM using developer tools, I determined each sentence is contained within a element whose class is sentence-and-translations. By finding all such elements, I could determine whether an audio example was missing by checking whether it contained an element whose aria-label attribute was volume-off.
For each relevant sentence, I would need to collect the actual text in question (by finding a ng-if attribute set to !vm.sentence.furigana, oddly). I also choose to store the sentence ID (a element with an ng-href attribute, contained within md-subheader-content), as my future self might make use of it for caching purposes.
Armed with my CSS Selectors, I set off to achieve the above.
(GentleHacker sidenote: Whenever I can use map I feel like a Wizard. This may express deep secrets about my psyche and I don't wish to dwell on it).
Shiny new buttons
Now we know what's missing, we can begin to compensate for said absence. This comprises constructing new buttons, adding a eventListener for click, and inserting them into the appropriate place in the DOM.
Now, you might be asking yourself, why use browser.runtime.sendMessage to call the API, instead of calling it directly via elevenAPI.streamAudio()? That is an excellent question and the answer, as it so often does, comes back to CORS.
Whereas previously, content scripts were afforded an exemption from labouring under the harsh realities of Cross-Origin-Resource-Sharing, modern browsers consider such practices... distasteful. Thankfully, we have a workaround: background scripts.
Background Scripts: The Intermediary
Background scripts load in the background, as you might imagine, and have access to the full gamut of WebExtension APIs. They can either persist, or load in response to certain events; The latter, non-persistent scripts will eventually be the only kind.
As such, it behoves us to write our script in a non-persistent manner, which is not at all arduous. It merely requires that listeners are top-level, and we avoid relying on global variables.
To whit:
Our manifest contains some new syntax! One advantage of vite-plugin-web-extension is that it allows us to define manifest.json in terms of the browser we're targetting. On Firefox, background scripts are simply called scripts, whereas on Chrome, they're called service_worker. Thankfully, it's trivial to account for both.
Speaking of trivial, background.ts isn't particularly impressive. It polyfills the browser APIs for that rascal Chrome, then adds a listener for messages and, if one is received, fires off streamAudio.
Triumph!
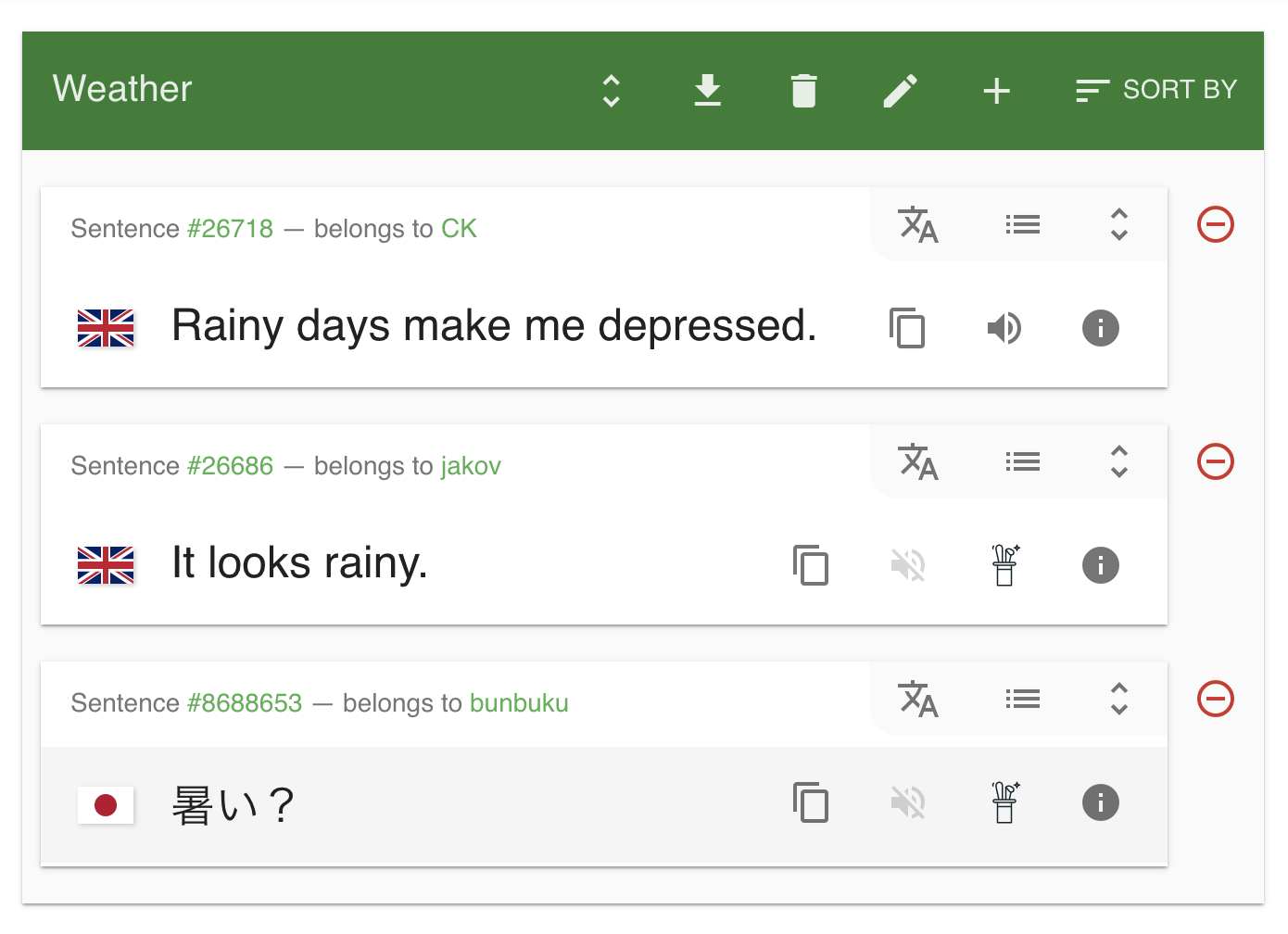
Click one of those buttons, gentle reader, and ElevenLabs will spin into action, generating you a lovely audio example. Marvellous.
Thank You, Gentle Reader
We have accomplished what we set out to do! We can access the ElevenLabs API and generate audio where missing, and we've done so in a such a way that we can easily extend it further.
Were I to spend more time working on this extension, I'd consider things such as:
Using IndexedDB to cache responses
Pulling down the full list of voices as part of the options, and allowing users to choose them in-app, on a per-language basis
Adding a translation challenge mode, where the listener hears a random sentence, then a pause, and must translate it themselves before hearing the "Correct" translation.
A universally available popup, allowing users to check selected text on any webpage to determine whether it's available on Tatoeba.org and, if so, hear a foreign translation in the language of their choice.
But these are tasks for another day.
Thank you again, gracious friend, for your time and attention. If you found this helpful I would sincerely appreciate a follow, like or comment. Sharing this article with your peers helps me greatly, as does following me on Mastodon, at https://tech.lgbt/@TheGentlehacker.
Ta-tah!



